Why You Need a Context Layer for Your Agent
AI agents start fresh every conversation, forgetting your business context. Learn why context windows aren't the solution and what a proper context layer actually does.
AI agents start fresh every conversation, forgetting your business context. Learn why context windows aren't the solution and what a proper context layer actually does.
Stay updated
Get notified when we publish new research on AI memory and agents.
If you've used AI agents for anything real, you've hit this wall. Not the "it's dumb" wall. The "it starts fresh every time" wall.
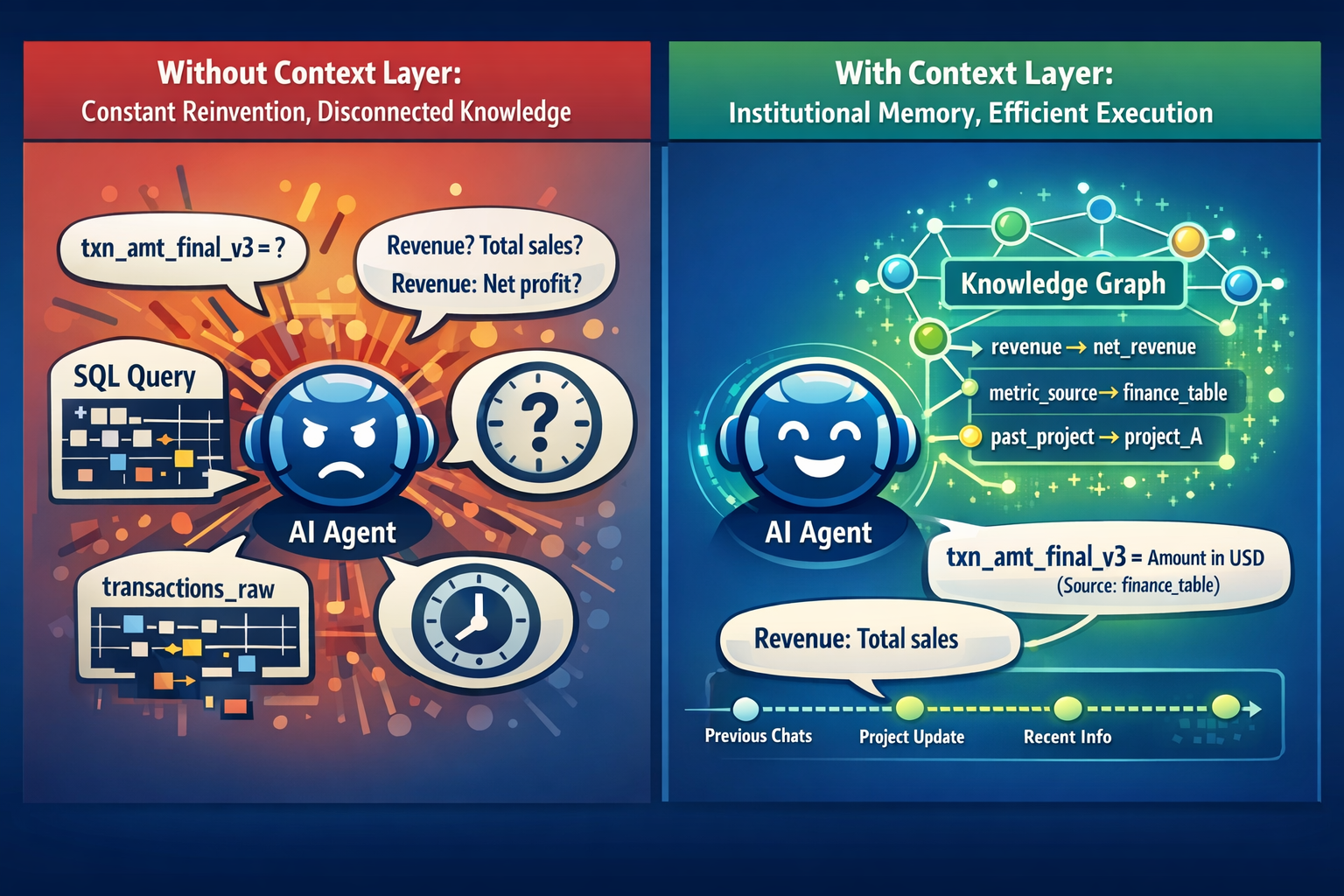
Every new conversation, you're re-explaining your world. Your tech stack. Your data model. The fact that txn_amt_final_v3 exists because someone on the team made it three years ago and left, and nobody renamed it. That "revenue" means net revenue, not GMV. That the fiscal year starts in April. You're onboarding the same brilliant person every morning and they have complete amnesia.
This is the context problem. And it doesn't go away by switching models or writing better prompts.
A context layer is the persistent, structured layer between your organization's knowledge and your AI agent. Not a prompt. Not a vector store full of document chunks. It's the thing that gives an agent actual understanding of your world. What things mean, how they relate, when they changed, and where that information came from. Think of it as the institutional memory your agent never had.
Without one, every agent interaction starts from zero. With one, the agent already knows your business.
Even within a single session, agents degrade. I've had Claude help me build something for three hours, then suggest we build the exact thing we just built. Same session. Same conversation. It didn't forget. It drowned. The context window fills up like a junk drawer. Old instructions, stale code blocks, abandoned tangents. Everything piles into one finite buffer and the model loses the plot.
Across sessions, it's worse. Every new chat is a blank slate. You're back to "I use Postgres, my tables are structured like this, the business logic works like that..."
The intuitive fix is longer context windows. Claude has 200K tokens. Gemini has a million. But a million tokens just means a bigger junk drawer. Research on "lost in the middle" shows models struggle to use information placed in the middle of long contexts. More recent work on "lost in the haystack" found that smaller pieces of relevant information become harder to find as context grows. The problem isn't capacity. It's curation.
Every organization runs on knowledge that nobody wrote down. "Revenue" means three different things depending on which team you ask. The clean table in the warehouse is the one you trust, not the raw dump nobody should be querying. That column labeled is_active hasn't meant what it says since the migration last year.
This shows up across every use case where agents touch real work:
Data analysis. Your agent writes perfect SQL against transactions_raw instead of transactions_clean because nobody told it which table your team trusts. The numbers come back wrong. Someone puts them in a deck. You catch it on Thursday.
Customer support. A customer asks about a plan your company killed last quarter. The agent finds the old pricing page in the knowledge base and walks them through signing up for something that no longer exists.
Software engineering. You ask an agent to add a new API endpoint. It scaffolds everything from scratch instead of using the internal helpers your team built six months ago. The code works. It just doesn't match anything else in the repo.
Same root cause every time. The agent has access to tools and instructions, but not the context that makes them useful.
The instinctive fix is RAG. Dump your docs into a vector database, let the agent search them. It helps, but not enough. RAG retrieves information. What agents actually need is understanding. A document that says "revenue is recognized upon delivery" doesn't help when the actual logic lives across a dozen tables with naming conventions only your team knows.
A context layer needs to do four things well.
Agent onboarding. Persistent memory that survives across sessions. Your agent should already know your stack, your conventions, your domain on conversation two. You shouldn't have to re-explain. The context layer holds what was learned and carries it forward, so every interaction builds on the last instead of starting over.
Temporal understanding. Facts change. Prices update. Products get discontinued. Policies get revised. A context layer needs to know that something was true in January but isn't true now. Otherwise you get the support agent confidently recommending a product that doesn't exist anymore. Or the data agent using a metric definition that was revised two quarters ago.
Relationships among entities. Not just documents, but structured connections. "This metric is derived from these two tables, owned by this team, updated weekly." That kind of explicit relationship lets an agent reason correctly instead of guessing from scattered text. Models are surprisingly good at working with structured, relationship-rich context. Much better than with walls of unstructured prose. Almost like they need a formal ontology for your business, even if nobody calls it that.
Auditability. Where did this context come from? A company wiki? An LLM inference? A manual entry from an engineer? How confident are we? When was it last verified? If you can't trace where the context came from, you can't trust it. And if you can't trust the context, you can't trust the agent. This obviously matters in regulated industries. But honestly it matters everywhere.
People are attacking this from different angles. GraphRAG builds knowledge graphs over documents so models can traverse relationships instead of just matching text chunks. Fast-graphrag and Mixture-of-PageRanks use PageRank-style scoring to surface what actually matters in a corpus, not just what's semantically similar to the query. Foundation Capital wrote about context graphs as the next enterprise infrastructure layer. Anthropic published their thinking on context engineering for agents. Microsoft Research published ACE, a framework where agents evolve and compress their own context over time instead of letting it rot.
Lots of smart work. Still no clean answer. Context windows will keep growing. Models will get better at attending to long inputs. But the fundamental issue isn't how much a model can hold. It's that nobody has built the layer that curates what goes in. The thing that knows your business definitions, tracks when they change, understands how your entities relate to each other, and delivers exactly the right context for the task at hand.
The model isn't the bottleneck. The context is. And that, for now, remains an open problem.