Every agent you've used has amnesia. Not partial memory loss or fuzzy recall but full reset. You start a new session and the agent knows nothing about anything you've discussed before. Your tech stack, your naming conventions, your business definitions are all gone. You are onboarding a brilliant new hire every morning, and every morning they remember nothing.
The Cost of Forgetting
Last month, a support agent at a mid-sized SaaS company promised a customer same-day resolution on a critical bug. The customer had been dealing with this issue across three separate tickets over two weeks. The agent had no idea. It pulled the standard SLA from documentation — 48 hours for non-enterprise accounts and quoted that confidently. What it didn't know: this customer had been explicitly promised priority handling by the VP of Customer Success in a call the previous week. That promise lived in a Slack thread the agent couldn't see and a memory system that didn't exist.
The customer churned. $80K ARR, gone. Not because the agent was wrong about the SLA. Because it didn't remember what the company had already committed to.
This is what memory failure looks like in production. Not a dramatic hallucination. A quiet, confident answer that ignores everything that came before.
Where This Fits
This is the second post in our series on the context layer for AI agents.
In part one, we argued that longer context windows won't save you. The problem isn't capacity but it's curation. A complete context layer needs four things: persistent memory (so you're not onboarding your agent from scratch every session), temporal understanding (so it knows what's current vs. outdated), relationships among entities (so it can connect facts, not just store them), and auditability (so you can trace where any answer came from).
Today we're going deep on the first: persistent memory.
Here's the core insight: memory isn't about storing facts. It's about representing relationships and time. "Revenue means net revenue" is not useful on its own. "Revenue means net revenue, calculated from transactions_clean, owned by the data platform team, updated weekly, redefined last quarter" is useful because it's a web of connections, not a sentence.
Most memory systems store sentences. That's why they fail.
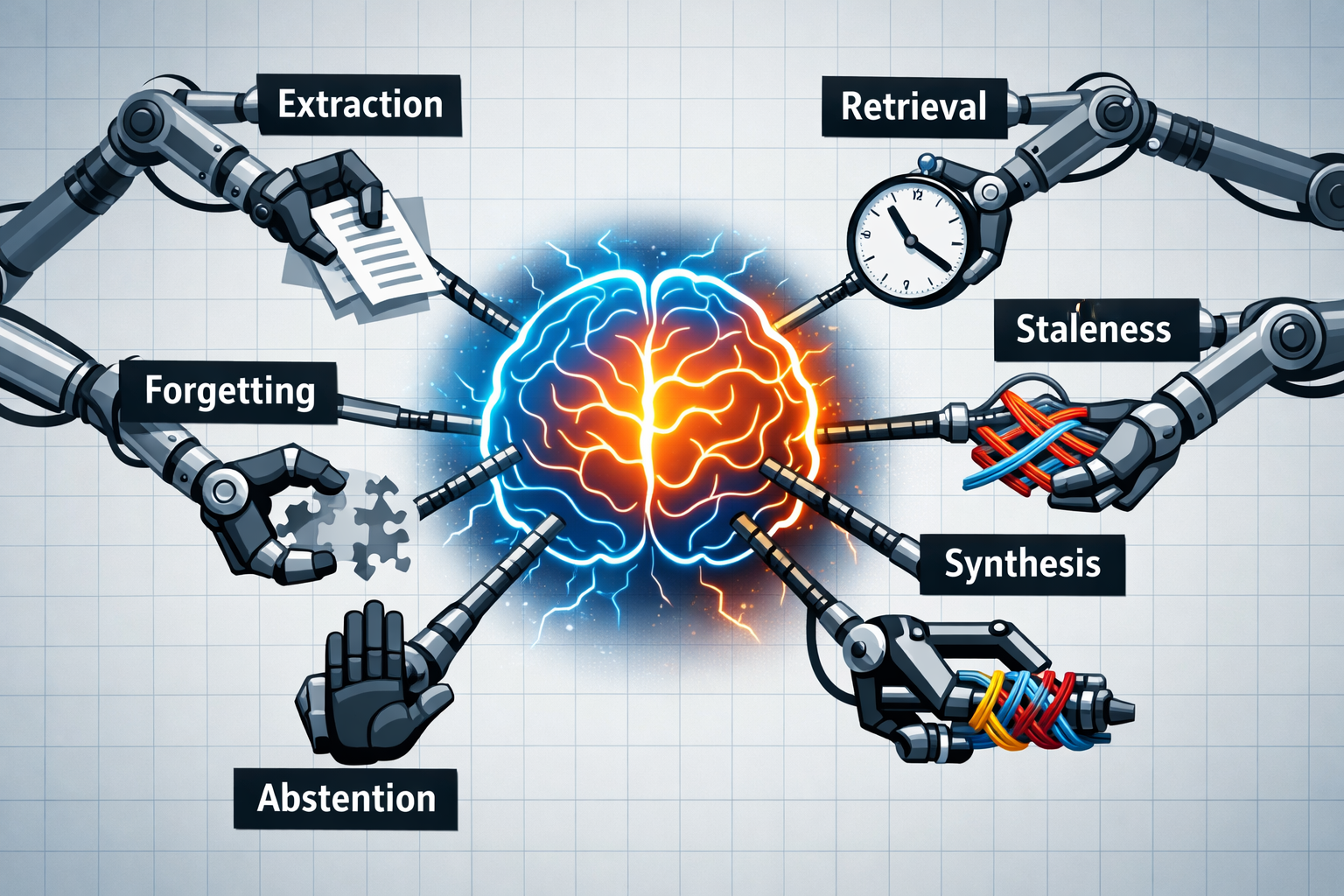
The Six Hard Problems
Persistent memory breaks down into six distinct challenges. Each has different failure modes, and solving one doesn't help with the others.
1. Extraction
The agent needs to identify what's worth remembering. This sounds simple until you realize that importance is contextual. "The user prefers Python" is clearly a fact. But what about "we tried approach X and it didn't work"? Or "the client seemed frustrated in that last call"?
Failure mode: An agent that extracts too little misses critical context. An agent that extracts too much drowns in noise. Most systems err toward too little because it's safer.
2. Retrieval
Storing facts is easy. Surfacing the right fact at the right time is hard.
When someone asks "what's our revenue model?", the agent needs to find relevant memories from potentially thousands. A fact about revenue from a finance discussion six months ago needs to appear when someone in product asks a tangentially related question today.
Failure mode: A sales agent is preparing a renewal proposal. Last quarter, the customer's CFO mentioned in a call that they're under budget pressure and need to consolidate vendors. That fact exists in the memory store. But the agent's retrieval query something like "customer contract details" doesn't surface it. The proposal goes out at full price. The renewal stalls.
The query space is enormous. Relevance is contextual. Keyword matching isn't enough.
3. Staleness
Facts change. Your pricing model from Q1 is wrong by Q3. The table schema migrated. A metric got redefined. A team reorganized.
If your memory system stores facts without timestamps or without any sense of when something was learned or whether it's still valid, you get confident answers built on outdated information.
Failure mode: The orders_clean table was deprecated in January. Your data agent is still querying it because that's what it learned three months ago, and nothing told it the world changed. The query runs. The numbers are wrong. A dashboard ships to executives with stale data. Nobody catches it for two weeks.
This is worse than no memory at all. Silence is recoverable. Confident wrong answers erode trust.
4. Synthesis
"What was my total spend across the three projects we discussed this month?"
No single stored memory answers this. The agent has to find relevant memories from different sessions, recognize they're related, and combine them correctly.
Failure mode: A customer asks an enterprise support agent: "How many outages have we had this quarter?" The agent finds two incidents from last month. It misses the third from six weeks ago because that conversation was with a different support rep, tagged differently, stored in a separate memory partition. The answer is wrong not because the data doesn't exist, but because the agent can't connect across sessions.
This requires understanding which memories relate to which and not matching keywords, but modeling relationships.
5. Forgetting
A memory system that only grows will drown in its own noise. Accumulated context from hundreds of sessions creates a haystack where every needle gets harder to find.
But deciding what to discard is genuinely hard. You don't know today whether a memory from last March will matter again in June. The throwaway comment about a customer's vacation plans might be irrelevant or it might be the context that makes a future interaction feel personal.
Failure mode: An agent's memory has grown to 50,000 facts over a year. Retrieval latency has crept up. Worse, old facts about deprecated products and churned customers keep surfacing, polluting answers with irrelevant context. But aggressive pruning risks deleting something that will matter later.
There's no clean solution here. Only tradeoffs.
6. Abstention
When the memory system has nothing relevant, the correct response is "I don't know."
Not a hallucinated answer assembled from vaguely adjacent facts. Not a confident guess. Silence, or an honest admission of uncertainty.
Failure mode: A customer asks about their custom pricing agreement. The memory system has nothing, the agreement was negotiated before the agent was deployed. Instead of saying "I don't have that information," the agent constructs an answer from standard pricing docs. The customer sees a number 40% higher than their actual rate. They call their account manager, furious.
Abstention is the hardest problem because it requires the agent to model its own knowledge boundaries. Almost nobody implements this well.
Where Current Systems Are
The industry has made real progress, and it's worth being specific about what exists.
OpenAI's ChatGPT memory stores discrete facts about users (roughly 30-40 per person) and injects them into the system prompt. "The user prefers dark mode." "The user works in fintech." This is sensible for a consumer product serving hundreds of millions of people. It handles extraction and basic retrieval. It was not designed for temporal awareness, synthesis, or relationship modeling and it doesn't pretend to be.
The memory startups went deeper:
- Mem0 does intelligent compression of conversations into stored facts, with a graph memory layer for capturing relationships between entities. It's a real attempt at the relationship problem.
- Zep built Graphiti, a temporal knowledge graph that handles fact invalidation: when new information contradicts old, the old fact gets marked as outdated while preserving history. This is one of the few production systems taking staleness seriously.
- Letta (the MemGPT team) built a tiered architecture inspired by operating systems—core memory stays in context always, archival memory is searchable long-term storage, recall memory covers conversation history. The tiering helps with the forgetting problem by creating natural boundaries.
Each solves a real piece of the puzzle. None solves all six.
What the Benchmarks Say
LongMemEval (ICLR 2025) was one of the first serious attempts to measure persistent memory capabilities. 500 questions, five capability dimensions, embedded in multi-session chat histories.
The results are instructive:
- Single-session fact extraction: Mostly handled. Commercial systems do okay here.
- Multi-session reasoning: The weakest category across the board. Connecting facts across separate conversations remains unsolved.
- Temporal reasoning: Sits in the middle.
- Abstention: Barely addressed by any system.
Evo-Memory from DeepMind and UIUC (November 2025) asked a harder question: can agents learn from experience? Not just recall what happened, but improve their approach over time by reusing strategies that worked before.
The answer: current agents mostly don't learn. They store, they retrieve, but they don't compound.
The implication is uncomfortable: If you're building an agent that needs to remember anything meaningful across sessions, you're on your own. The foundation models won't save you. This is infrastructure you have to build.
Why Flat Memory Can't Get There
The multi-session reasoning gap makes something obvious: flat fact stores can't close it.
Here's a concrete example. An analyst tells your agent:
"Revenue means net revenue, calculated from the transactions_clean table, owned by the data platform team, updated weekly, with the definition revised last quarter."
A flat memory system stores this as a sentence, a blob of text to be retrieved when someone searches for "revenue."
But this isn't one fact. It's a structure:
METRIC: Revenue
├── definition: net revenue (not GMV, not gross)
├── source: transactions_clean table
│ └── owner: Data Platform team
│ └── refresh: weekly
└── history: definition changed Q3 → Q4
When someone asks "where does revenue come from?", you need to traverse to the source. When someone asks "who owns this metric?", you need to traverse to the team. When someone asks "has this definition changed?", you need to traverse to the history.
A sentence can't do this. A graph can.
This is why the industry is converging on structured memory representations. Foundation Capital calls them context graphs — knowledge structures that capture not just facts but decision traces, the "why" behind organizational knowledge. Their thesis: the next generation of enterprise software will be built on systems of record for decisions, not just data.
The vocabulary varies. Context graphs, knowledge graphs, ontologies, semantic layers. The core insight is the same: relationships between facts matter as much as the facts themselves. Store sentences and you get search. Store structure and you get reasoning.
What's Still Open
The shape of good persistent memory is getting clearer. The hard problems remain hard:
- Building structured representations at scale is still largely manual. Someone has to define what connects to what.
- Temporal reasoning in production is mostly ad hoc. Zep's Graphiti is a notable exception.
- Forgetting is heuristic-based at best. No principled framework exists.
- Multi-agent memory (agents in a swarm pooling what they've learned) is barely explored.
- Abstention has no standard approach. Most systems just guess.
The benchmarks are maturing too. Letta showed that a basic file-based memory system scores surprisingly well on existing benchmarks which suggests the benchmarks don't yet capture what actually matters in practice.
We are early. The pieces are lining up. But persistent memory in production—memory that handles all six problems is still infrastructure you have to build yourself.
What Comes Next
Persistent memory is foundational, but it's only one piece of the context layer.
An agent that remembers everything but can't tell you when something was true has a different problem: temporal blindness. A customer's support tier changed from Gold to Silver in February. Your agent just promised them Gold level SLA. The orders_clean table was deprecated in January but your agent is still querying it. These aren't memory failures. They're failures to track how facts change over time.
And an agent that knows facts but not how they connect, which metric comes from which table, owned by which team will still struggle to reason across sessions.
Memory is necessary. It's not sufficient.
In the next post, we'll go deep on temporal understanding: what it takes to build systems that know the difference between what was true and what is true.
This is part 2 of our series on the context layer. Read part 1: Why You Need a Context Layer for Your Agent