Blog
Deep dives into context infrastructure, agent architectures, and the systems that help AI reason over relationships.

Cloudflare Agent Memory: When Memory Becomes Managed Infrastructure
Cloudflare's Agents Week announcement signals a shift: persistent memory is no longer a feature to build, it's infrastructure to consume. What the five-channel retrieval architecture and managed extraction pipeline mean for agent builders.
 Yash Goyal·May 14, 2026
Yash Goyal·May 14, 2026
Hypergraph Based Memory: Why Pairwise Graph Memory Isn't Enough for AI Agents
Most AI memory systems store knowledge as binary triples. Hypergraphs preserve the natural structure of multi-participant facts, setting a higher ceiling for what retrieval can recover.
Yash Goyal·Apr 20, 2026
What Ancient Sanskrit Solves in AI Memory
Pāṇini's 2,500-year-old kāraka roles provide a minimal, language-universal vocabulary for labeling how participants relate to actions — turning vague entity lookups into structured semantic search.
Yash Goyal·Apr 20, 2026
The Embedding Problem: Extracting Structure from Text
Text embeddings conflate structure — 'Alice gave Bob a book' and 'Bob gave Alice a book' have nearly identical embeddings. Structured extraction with Kāraka roles recovers what embeddings lose.
Yash Goyal·Apr 20, 2026
The Forgetting Problem: How Neuroscience Solves AI Memory
Not all memories are equal — episodic events should fade, semantic facts should persist, procedural skills should endure. Neuroscience-inspired memory types solve the forgetting problem for AI agents.
Yash Goyal·Apr 20, 2026
The Math Behind What Your Agent Remembers or Forgets
An ACT-R-inspired formula combining recency, frequency, salience, and confidence determines memory strength — governing what surfaces during retrieval and what fades into oblivion.
Yash Goyal·Apr 20, 2026
The Retrieval Problem: What Neuroscience Knows About Finding Memories
Embedding search alone misses structural connections. Dual-arm retrieval — combining hypergraph traversal with semantic search via Reciprocal Rank Fusion — covers both structure and similarity.
Yash Goyal·Apr 20, 2026
Lossless Claw: How DAG-Based Compression Stops AI Agents From Forgetting
How Martian Engineering's DAG-based compression replaces truncation with hierarchical summaries. Why lossless session memory changes everything for long-running AI agents.
Yash Goyal·Apr 17, 2026
Tobi Lütke's QMD: Why Shopify's CEO Built His Own AI Memory System
How Shopify's CEO built an on-device search engine that gives AI agents persistent memory across sessions. Why local-first retrieval is the missing infrastructure for AI-first workflows.
Yash Goyal·Apr 17, 2026
Garry Tan's GBrain: How It Works + An Honest Review (2026)
What is GBrain? Inside Garry Tan's open-source AI memory system — the markdown brain, hybrid search, self-wiring graph, and dream cycle — plus an honest review of what it gets right and where it falls short.
Yash Goyal·Apr 14, 2026
Andrej Karpathy's LLM Wiki: Why the Future of AI Memory Isn't RAG
How Karpathy's wiki pattern replaces RAG with compiled knowledge that compounds. Why synthesis beats retrieval for AI memory systems.
Yash Goyal·Apr 14, 2026
LongMemEval Explained: The Benchmark That Tests Agent Memory
LongMemEval is the ICLR 2025 benchmark for evaluating long-term memory in conversational AI. Learn what it tests, why it's hard, and how to read benchmark claims critically.
Yash Goyal·Apr 11, 2026
Milla Jovovich's MemPalace: What a 100% LongMemEval Benchmark Score Reveals About AI Memory Design
MemPalace achieved the highest local-only retrieval score on LongMemEval by storing everything verbatim. We analyze what this reveals about the extraction vs. verbatim debate in AI memory design.
Yash Goyal·Apr 11, 2026
KAIROS and the End of Stateless Agents: What Anthropic's Architecture Reveals About Production Memory Systems
The leaked KAIROS system inside Claude Code reveals a paradigm shift in how coding agents handle memory. Learn what append-only logs, async consolidation, and cross-device sync mean for production agent architectures.
Yash Goyal·Apr 6, 2026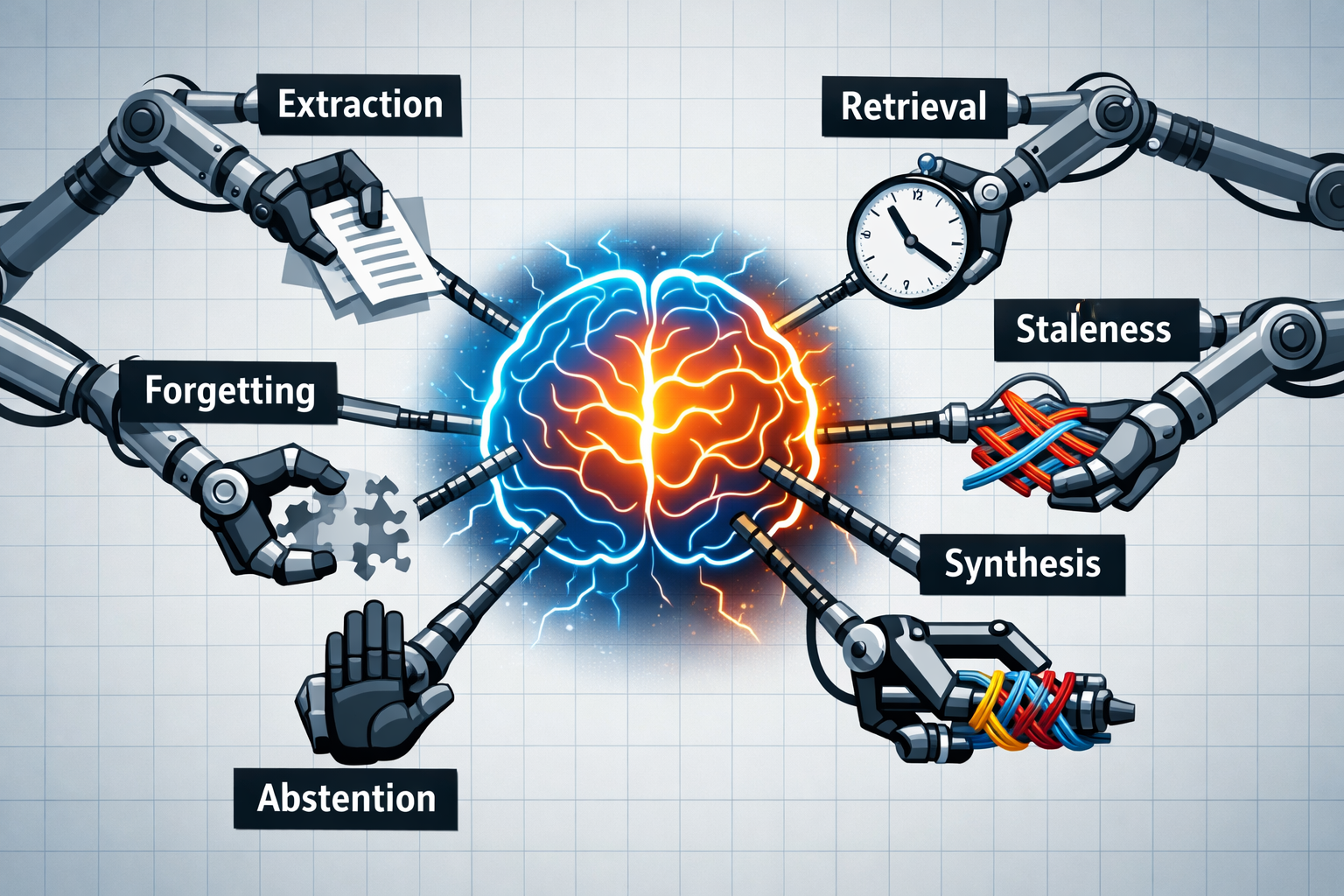
Persistent Memory for AI Agents - A Landscape
Every agent you've used has amnesia. Explore the six hard problems of persistent memory — extraction, retrieval, staleness, synthesis, forgetting, and abstention — and why flat fact stores can't solve them.
Yash Goyal·Mar 13, 2026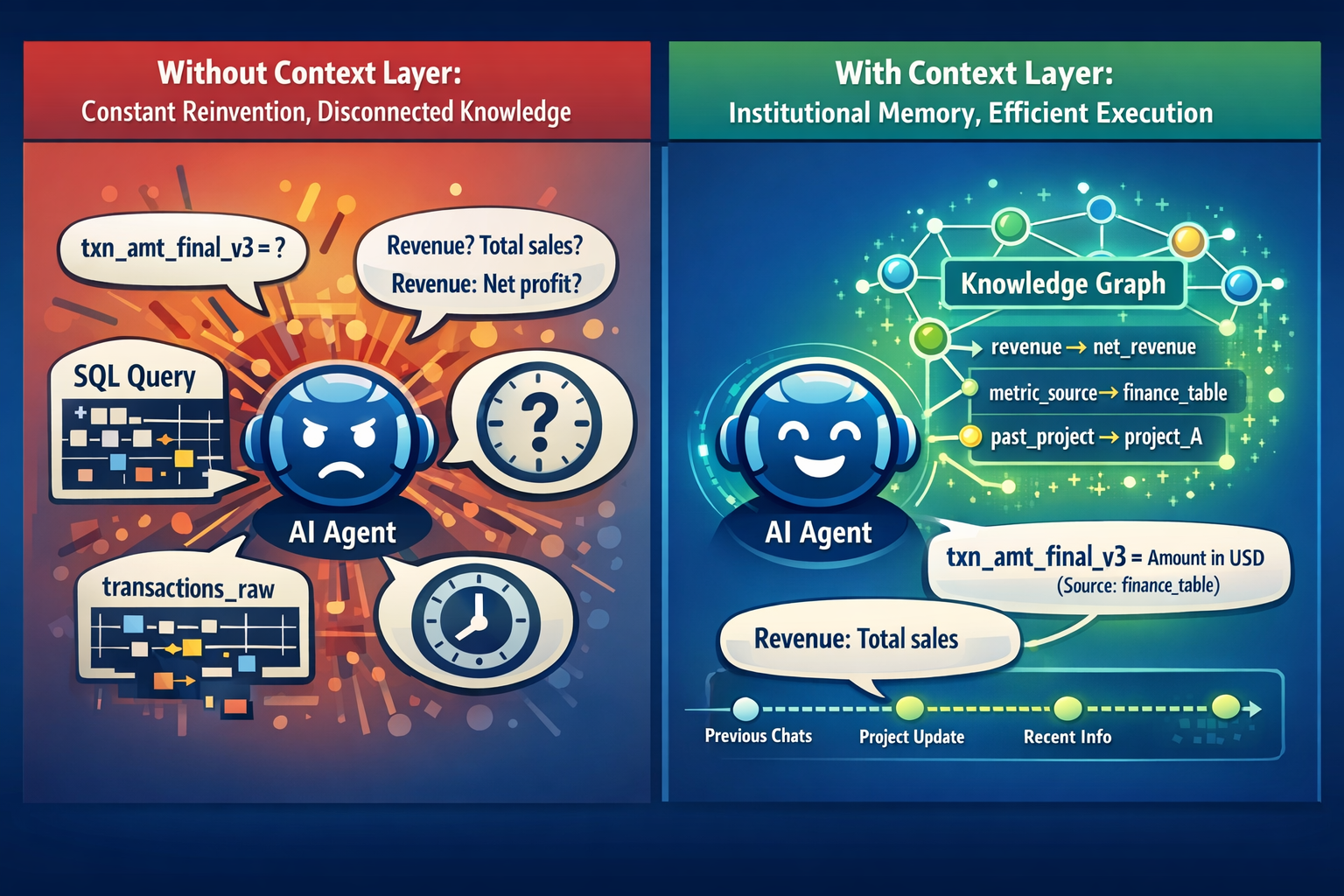
Why You Need a Context Layer for Your Agent
AI agents start fresh every conversation, forgetting your business context. Learn why context windows aren't the solution and what a proper context layer actually does.
 Harshid Wasekar·Mar 7, 2025
Harshid Wasekar·Mar 7, 2025